Alarms
The operation of the replication service can be monitored by the administrator of the cluster through the status of the following alarms visible in the specific section:
- Synchronisation Readiness: represents whether local node is ready to synchronise its data.
A node could be not ready to synchronise if, during its addition to the cluster or during the last update, it couldn't complete the [re]initialisation ([re]provisioning) procedure. In this case the only way to restore its operation is to run the IAS setup package again, which will complete the initialisation of the node. - Synchronisation Activity: represents the status of synchronisation operations in the local node.
If a node is not ready to synchronise, this alarm isn't evaluated as it would be meaningless.
Otherwise, it shows if the node is synchronising with the expected remote node (green), with a different node (yellow), or with no other node at all (red). - Time Alignment: shows whether local node and its expected remote node have the same time configuration, and their system time is the same.
All the nodes times must be aligned in order to allow the cluster to work correctly.
If local and remote times are aligned the alarm will be green, otherwise it will be red.
Event notifications
While the Replication Service is running, some events are notified to the cluster administrator to let him identify any potential issue.
Readiness events
When a node is not ready to synchronise its data, it reports the problem with a sync not ready notification that contains the problem that prevents its readiness.
When that problem is solved, the node notifies that it's back to normal with a sync ready notification.
Synchronisation events
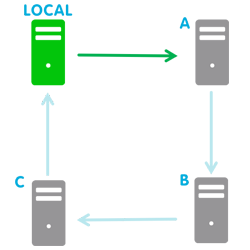
In normal conditions any cluster node will synchronise with its successor in the cluster topology.
No notification is reported until any event changes this situation.
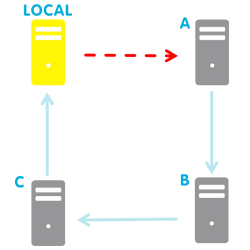
If local node fails the synchronisation with its successor, a failure notification is sent.
Then the node tries to synchronize with the other nodes of the cluster and, if successful, it sends a failover notification.
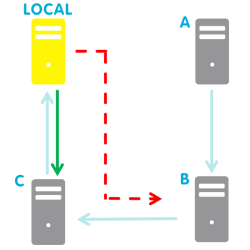
In this situation the remote node used for the synchronisation will not change unless a new failure occurs.
A new failure notification is sent for each synchronisation failure with a remote node, and it will report the failure reason.
A new failover notification is sent for each successful remote node change.
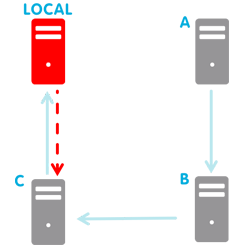
If local node fails to synchronise with every other node in the cluster, it sends a no available node notification.
After any failure, local node tries periodically to synchronise with its successor and, whenever it succeeds, it sends a failback notification to signal that its normal behaviour has been restored.
Time alignment events

When time difference between a node and its successor is too high (i.e. over 15 seconds), data replication is inhibited to prevent unexpected behaviours, and a time not aligned notification is sent.

A time aligned notification will then signal when time difference is back to normal.